
Product Description
The Papyrus Business Designer is a modern WYSIWYG design tool for easy definitions when digitizing business content with a self-learning user trained capture capability. Document structures and extraction definitions can be created faster and better than ever before.
It specializes in supporting business capture and OCR needs during content and case-management operations, such as extracting/indexing documents in the business case (on the fly, on demand), but also lifting fields from arbitrary documents, again ad-hoc and on the fly. This is possible because the Papyrus Business Designer/Capture does not require IT involvement, it gives all the power into the hands of the actual users of the application
Any document can be extracted on the fly, regardless whether a document template has been created for it or not. Extraction definitions created by one user can be shared with other users or entire departments.
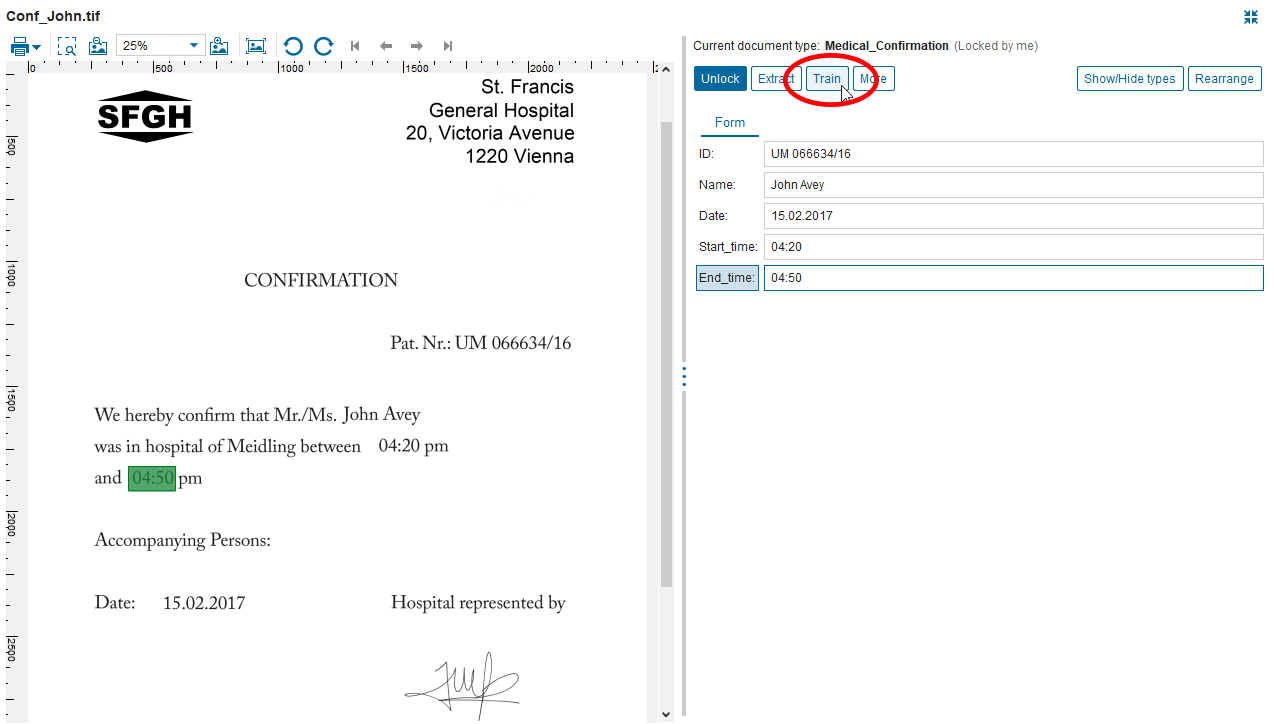
To lift a field from a document, the business user simply drags the text/area that is to be extracted from the document onto a pane. For its OCR/ICR/Classification capabilities the Papyrus Business Designer relies on the IDEX-Engine, also used in the Papyrus Recognition Server, which is a prerequisite for the deployment of Papyrus Business Designer.
Key Benefits
- User trained capture capability
- Increased efficiency for content digitizing: document types and extraction definition can be created faster and better than ever before.
- Easy and clear application for business users supported by user-trained technologies to create an extraction definition
- Excellent tool for both business and IT allowing a perfect collaboration
- Optimal collaboration and assuring the best results by utilizing Papyrus change management
- Recognition quality assurance supported by automatic evaluation of the extraction results for supervisor decision making
Functions
- Document types and extraction definitions for business users
- User trained extraction with sample documents
- Change and release management of document definitions
- Recognition quality evaluation
Document Extraction Definitions
- Upload document samples
- Create new document types
- Create new data fields and UI form elements: specify element type, region, keywords, etc.
- Extract and paste document content into an existing field form by drag and drop
- User trained document definitions fully compatible with Papyrus Capture Designer allowing to refine certain field definitions by extraction development experts for best performances
- Rearrange or delete fields from form
Training
- Create implicit training data during creation of new fields
- Train extraction definitions with training data collected during fields manipulations (creation or update)
- Refine extraction definitions by deleting training data and retraining
Classification
- Classify new document samples
- Correct document sample categories
Change Management
- Manage full life cycle of document structure and extraction definition
- Define change management process: private and group development
- Deactivate or restore document and extraction definitions to last productive version
- Delete not productively used document definitions
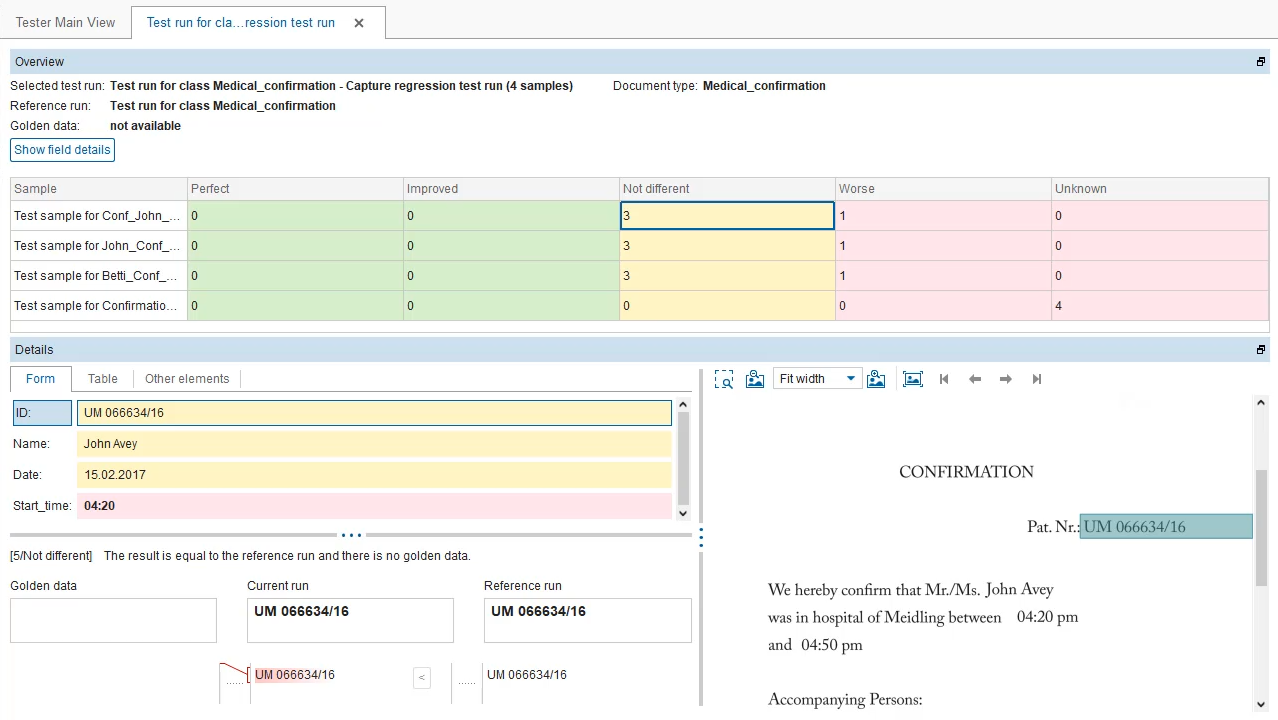
Recognition quality assurance
- Recognition results representation for the trained document samples
- Automatic compare with the reference data from the previous productive version of the extraction definition
- Representation of the extraction and comparison results in the optimal way to the supervisor
Integration
Papyrus Business Designer/Capture is natively integrated within Papyrus Adaptive Case Management (ACM) and is fully supported by it.
IT-experts can do extensions of the created extraction definition also with the Papyrus Designer Capture in case complex extraction logic is required.
Formats
- TIFF 6.0 or higher (also multi-page)
- JPEG
- BMP
- GIF
- PNG
- PDF 1.4 or higher
- PDF/A (ISO 19005)
- Office formats:
- DOC/DOCX/DOCM/ODT
- PPT/PPTX/PPTM/ODP
- XLS/XLSX/XLSM/ODS
Prerequisites
- Windows 7 or later, Windows Server 2012 or later
- Standard office PC
- Minimum display resolution of 1280x1024
- Papyrus WebRepository
- Papyrus Recognition Server
- Papyrus Capture /Office-In for office formats support
- Papyrus PDF-in for native PDF support
- Anonymized document samples for training (GPDR conform)