


IBM and Papyrus Software:
Advanced AI for Innovative
Value Stream Implementation
GROUNDBREAKING PARTNERSHIP
View Report














Revolutionize your customer communication with Papyrus Software! Consolidate and handle all types of document output from a sleek platform, design and deliver instantly complex business documents with ease.
CCM Platform - A Central Hub
With one set of definitions, share across channels and applications seamlessly saving up to 50% in time empowering your business with new standards in CCM. Our customers have achieved 20x daily communication production, with business users taking care of 99% of overall business communication. Empower your business and set new standards in CCM.
Review: Aim higher with Papyrus CCM
Are you tired of wasting time searching for crucial information? With Papyrus, you can easily access any document, email, video or file with just a few clicks.
Unleash the Power of Unified Content!
Collaborate seamlessly with your team on a single source of truth, eliminating information silos. Papyrus ensures the complete security and lifecycle of every piece of content, so you can focus on what matters most - your business.
Research: IDC | Content accessible any time anywhere


Cut processing time from days to hours by capturing meta-data the moment your mail arrives.
Self-Learning | User-Trained Technology
The system gets smarter with every document figuring out what matters using a self-learning, user-trained technology via one single definition. All types of structured and unstructured communications (including handwriting) are handled and extracted data is directly routed to the archive and clerks inbox. 'Cut the monotonous busywork, make faster decisions - that's what Papyrus does'.
Watch: Inbound Mail Capture Demo
Case Study: Tryg Insurance Claims Handling Automation
Designers? Coders? Who needs them? With Papyrus Converse, you're in the driver's seat. Imagine turning your ideas - the whole way you work with customers - into reality, right on the screen.
Experience a Mind-Shift
No more clunky software, no more waiting on IT. This is about taking control, doing amazing things faster than you ever thought possible. Trust us, this technology is the future.
Showcase: Design and Execute your Value Stream
Spotlight: How AI and NLP in Converse transform BPM and the Programming industry

Imagine understanding a customer's entire journey, not just parts of it. That's what Adaptive Case Management does. Your system learns as your customers interact and suggests the perfect next step, exactly when you need it.
Manage any type of work!
Forms, data, tasks, decisions - everything is synchronized and designed to feel effortless for the customer and powerful for your team."
Showcase: Design your registration process
Watch: How you design a Value Stream process
Learn: Digital transformation of forms applications
Case Study: Transforming Case Management from physical to digital
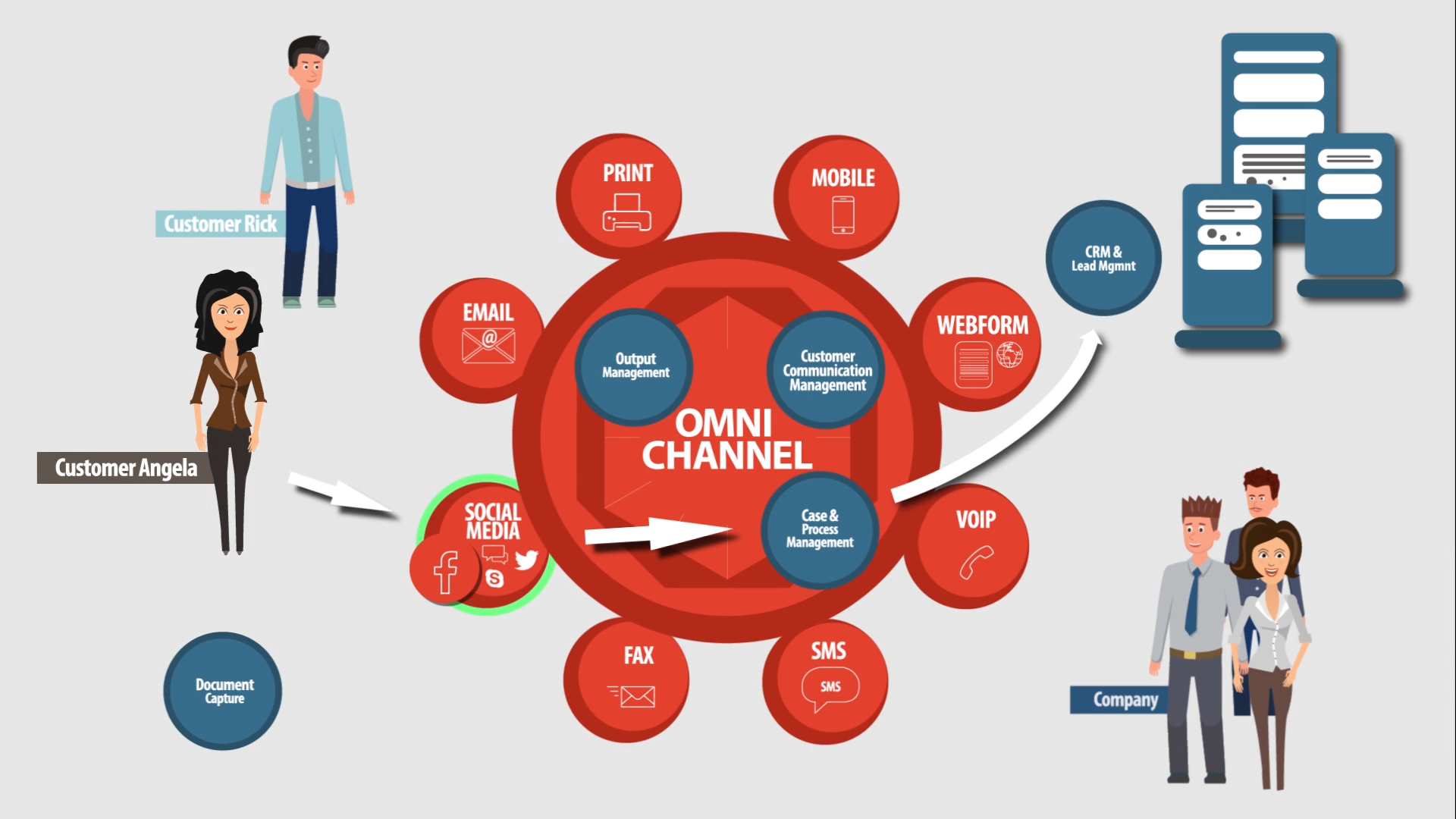
Your customers don't think in channels! They expect a seamless experience across all channels of communication. Papyrus Omni-Channel Architecture understands this and provides just that. With Papyrus, your customers can switch device and channels without any interruption. The conversation flows seamlessly, and your customers never feel lost. The platform not only tracks but understands their interactions, ensuring that the conversation never stalls. Give your customers the experience they deserve with Papyrus Omni-Channel.
Explore: Digital Communication Hub
Showcase: Self-Service for Customers

Output Management
Forget juggling different systems. One for email, one for print, another for SMS... that's very difficult to handle. With Papyrus, you create everything just once. A letter, a statement, a complex interactive form - it's instantly transformed to the format and channel of your customer needs. Web, email, mobile phone, printed mail, done. Best of all, you get real-time feedback so you can constantly improve.
The product really stands out as a leader in digital ADF
Rich Huff/Madison Advisor
Imagine running your business flawlessly, not just in the office, but everywhere. Say goodbye to clunky, siloed apps and hello to Papyrus Mobile Business Solutions - the all-in-one platform that liberates your team. Papyrus is native on all devices, ensuring seamless continuity. Deploy it in days, on-premises or private cloud, with full GDPR compliance. Security, simplicity, and freedom - all in one place.
Watch: Papyrus Mobile Business Solutions

Papyrus Software customers from some of the world’s leading companies gave an average rating of 4.5 out of 5 stars in the Customer Communications Management market, as part of the Gartner Peer Insights program.
Learn More★★
★★★
Of the 76 reviewers, 43 gave Papyrus Software 5 stars
91%
Reviews Papyrus Software received of 4 stars or higher
Our customers are proud of the exciting apps they create with Papyrus - as are we
Connect with us at leading technology conferences worldwide.
Stay informed with our newest insights, announcements, and thought leadership
Papyrus Software, a global leader in enterprise solutions, has been honored with the prestigious Document Manager Project of the Year Award. This accolade celebrates the groundbreaking digital transformation at Utmost Life and Pensions, a UK-based insurer. The project serves as a compelling model for how strategic vision and innovative technology can drive radical, remarkable change across the insurance landscape.
We’ve all been there: staring at a 2,000-page committee report or a mountain of incoming claims, trying to find that one needle of information in a haystack of data. According to Gartner, nearly 36% of workers struggle just to access relevant information. We aren’t just working; we’re sifting. But what if you didn’t have to search? What if you could just ask?
I recently sat in the audience at our Open House Global, listening to Andreas Stemick from BDO. I’ve seen many presentations on digital transformation, but this was different. It was a wake-up call. When Mr. Stemick displayed the data, the room went quiet: Cybercrime is now effectively the world’s fourth-largest economy.













